官方微信
手机客户端
设为首页
收藏本站
扫一扫,关注我们
QQ登录
微信登录
登录
注册
我的空间
我的消息
我的积分
我的收藏
我的好友
我的相册
我的道具
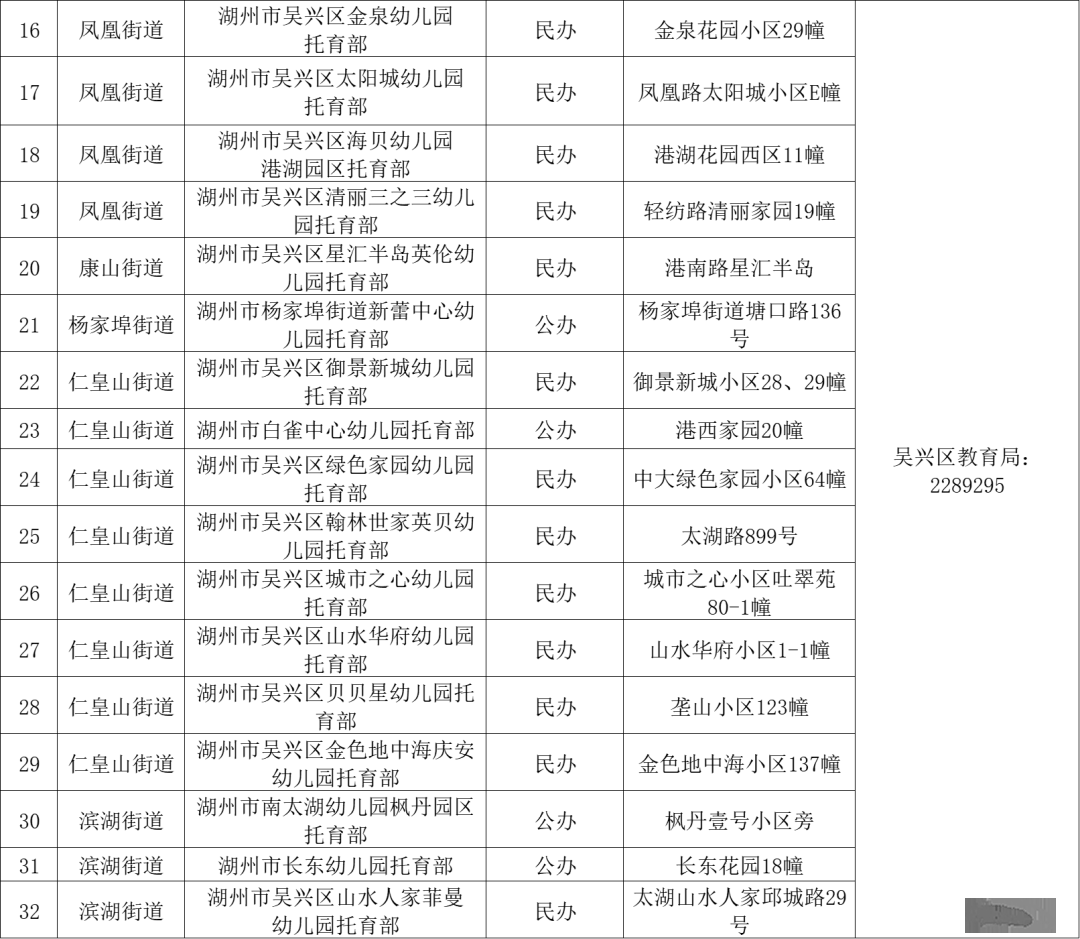
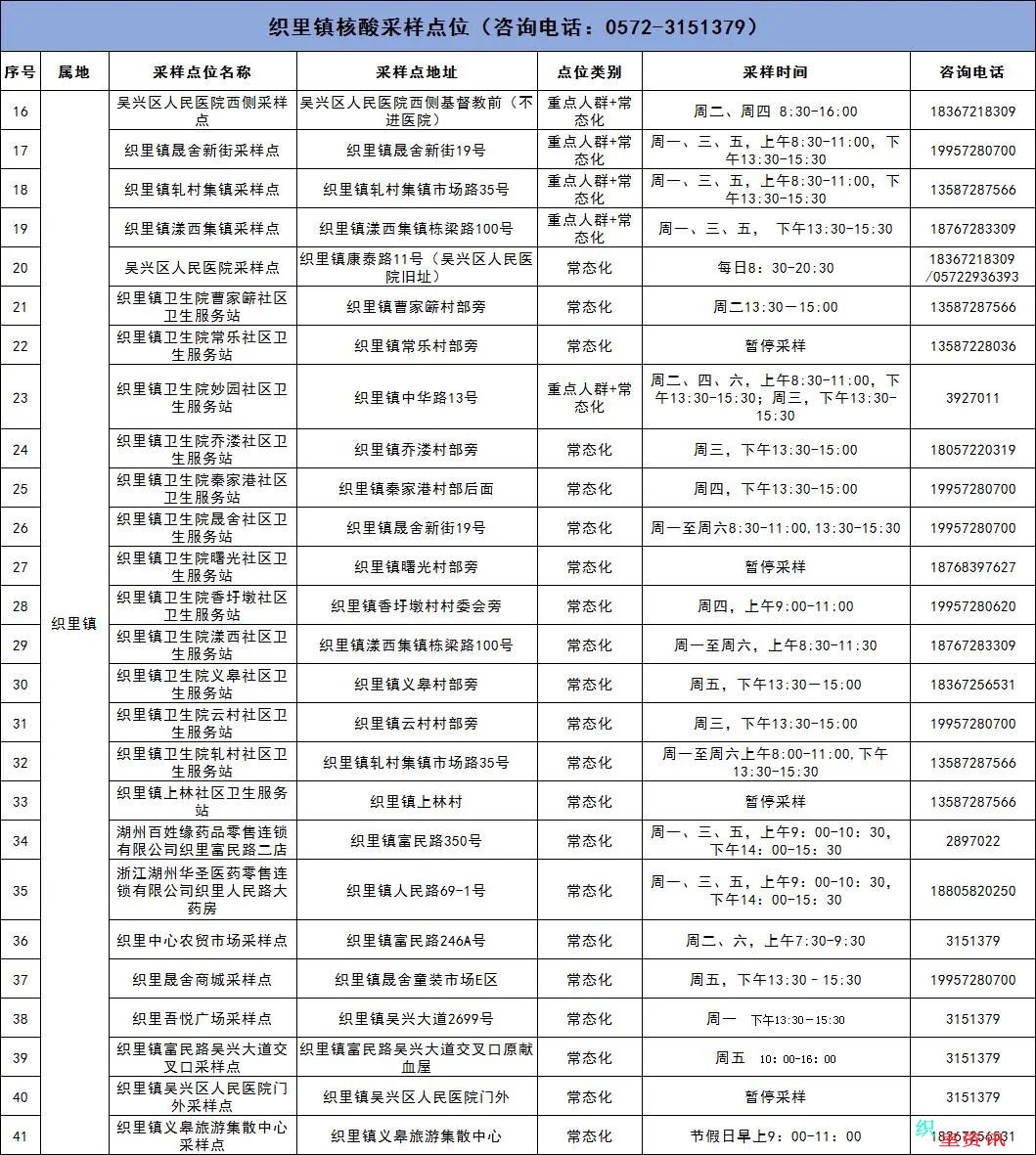
帐号设置
退出登录
免费发布信息
首页
Portal
新闻资讯
论坛
BBS
城事杂谈
求职招聘
房屋出租
织里跳蚤
房产资讯
关于我们
导读
首页
房产
装修
亲子
婚嫁
美食
汽车
旅游
娱乐
信息
求职
租房
二手房
招聘
拼车
二手车
服务
生活服务
城事杂谈
跳蚤市场
便民服务
社区
城事杂谈
情感天空
户外旅游
房产楼市
装修装饰
美食天地
当前位置:
»
论坛
›
城市服务
›
电脑维修
›
帖子
@所有织里人,这份国庆假期安全提
节前这场新闻发布会聚焦治安与共富
师傅,不好了!“二师兄”掉在高速
[ 电脑维修 ]
天啊噜,眼镜布竟然不是用来擦眼镜的!
[ 理财 ]
实现内外双循环,必须办理这三大问题!
[ 汽车天地 ]
广州车展|李凤刚:全新奥迪A5L将成为最
[ 房产资讯 ]
上海涨0.3%!深圳涨0.1%!房价开涨了!
[ 理财 ]
13个月以来首次转涨!70城房价出炉,房地
返回列表
发帖
回复
查看:
411
|
回复:
0
GPU的历史性时刻!
[复制链接]
admin
admin
当前在线
积分
311232
关注TA
发消息
发表于 2023-11-20 19:15:03
|
来自:中国浙江湖州
|
显示全部楼层
|
阅读模式
8月23日,GPU巨头Nvidia发布了2023年二季度财报,其结果远超预期。总体来说,Nvidia二季度的收入达到了135亿美元,相比去年同期增长了101%;净利润达到了61亿美元,相比去年同期增长了843%。Nvidia公布的这一惊人的财报一度在盘后让Nvidia股票大涨6%,甚至还带动了众多人工智能相关的科技股票在盘后跟涨。
Nvidia收入在二季度如此大涨,主要靠的就是目前方兴未艾的人工智能风潮。ChatGPT为代表的大模型技术从去年第三季度以来,正在得到全球几乎所有互联网公司的追捧,包括美国硅谷的谷歌、亚马逊以及中国的百度、腾讯、阿里巴巴等等巨头。而这些大模型能进行训练和推理的背后,都离不开人工智能加速芯片,Nvidia的GPU则是大模型训练和推理加速目前的首选方案。由于个大科技巨头以及初创公司都在大规模购买Nvidia的A系列和H系列高端GPU用于支持大模型训练算力,这也造成了Nvidia的数据中心GPU供不应求,当然这反映到财报中就是收入和净利润的惊人增长。
事实上,从Nvidia的财报中,除了亮眼的收入和净利润数字之外,还有一个关键的数字值得我们关注,就是Nvidia二季度的数据中心业务收入。根据财报,Nvidia二季度的数据中心业务收入超过了100亿美元,相比去年同期增长171%。Nvidia数据中心业务数字本身固然非常惊人,但是如果联系到其他公司的同期相关收入并进行对比,我们可以看到这个数字背后更深远的意义。同样在2023年第二季度,Intel的数据中心业务收入是40亿美元,相比去年同期下降15%;AMD的数据中心业务收入是13亿美元,相比去年同期下降11%。我们从中可以看到,在数据中心业务的收入数字上,Nvidia在2023年第二季度的收入已经超过了Intel和AMD在相同市场收入的总和。
这样的对比的背后,体现出了在人工智能时代,人工智能加速芯片(GPU)和通用处理器芯片(CPU)地位的反转。目前,在数据中心,人工智能加速芯片/GPU事实上最主流的供货商就是Nvidia,而通用处理器芯片/CPU的两大供货商就是Intel和AMD,因此比较Nvidia和Intel+AMD在数据中心领域的收入数字就相当于比较GPU和CPU之间的出货规模。虽然人工智能从2016年就开始火热,但是在数据中心,人工智能相关的芯片和通用芯片CPU相比,获得的市场份额增长并不是一蹴而就的:在2023年之前,数据中心CPU的份额一直要远高于GPU的份额;甚至在2023年第一季度,Nvidia在数据中心业务上的收入(42亿美元)仍然要低于Intel和AMD在数据中心业务的收入总和;而在第二季度,这样的力量对比反转了,在数据中心GPU的收入一举超过了CPU的收入。
这也是一个历史性的时刻。从上世纪90年代PC时代开始,CPU一直是摩尔定律的领军者,其辉煌从个人电脑时代延续到了云端数据中心时代,同时也推动了半导体领域的持续发展;而在2023年,随着人工智能对于整个高科技行业和人类社会的影响,用于通用计算的CPU在半导体芯片领域的地位正在让位于用于人工智能加速的GPU(以及其他相关的人工智能加速芯片)。
摩尔定律的故事在GPU上仍然在发生
众所周知,CPU的腾飞离不开半导体摩尔定律。根据摩尔定律,半导体工艺特征尺寸每18个月演进一代,同时晶体管的性能也得大幅提升,这就让CPU在摩尔定律的黄金时代(上世纪80年代至本世纪第一个十年)突飞猛进:一方面CPU性能每一年半就迭代一次,推动新的应用出现,另一方面新的应用出现又进一步推动对于CPU性能的需求,这样两者就形成了一个正循环。这样的正循环一直到2010年代,随着摩尔定律逐渐接近物理瓶颈而慢慢消失——我们可以看到,最近10年中,CPU性能增长已经从上世纪8、90年代的15%年复合增长率(即性能每18个月翻倍)到了2015年后的3%年复合增长率(即性能需要20年才翻倍)。
但是,摩尔定律对于半导体晶体管性能增长的驱动虽然已经消失,但是摩尔定律所预言的性能指数级增长并没有消失,而是从CPU转到了GPU上。如果我们看2005年之后GPU的性能(算力)增长,我们会发现它事实上一直遵循了指数增长规律,大约2.2年性能就会翻倍!
同样是芯片,为什么GPU能延续指数级增长?这里,我们可以从需求和技术支撑两方面来分析:需求意味着市场上是不是有应用对于GPU的性能指数级增长有强大的需求?而技术支撑则是,从技术上有没有可能实现指数级性能增长?
从需求上来说,人工智能确实存在着这样强烈需求。我们可以看到,从2012年(神经网络人工智能复兴怨念开始)到至今,人工智能模型的算力需求确实在指数级增长。2012年到2018年是卷积神经网络最流行的年份,在这段时间里我们看到人工智能模型的算力需求增长大约是每两年15倍。在那个时候,GPU主要负责的是模型训练,而在推理部分GPU的性能一般都是绰绰有余。而从2018年进入以Transformer架构为代表的大模型时代后,人工智能模型对于算力需求的演进速度大幅提升,已经到了每两年750倍的地步。在大模型时代,即使是模型的推理也离不开GPU,甚至单个GPU都未必能满足推理的需求;而训练更是需要数百块GPU才能在合理的时间内完成。这样的性能需求增长速度事实上让GPU大约每两年性能翻倍的速度都相形见拙,事实上目前GPU性能提升速度还是供不应求!因此,如果从需求侧去看,GPU性能指数级增长的曲线预计还会延续很长一段时间,在未来十年内GPU很可能会从CPU那边接过摩尔定律的旗帜,把性能指数级增长的神话续写下去。
GPU性能指数增长背后的技术支撑
除了需求侧之外,为了能让GPU性能真正维持指数增长,背后必须有相应的芯片技术支撑。我们认为,在未来几年内,有三项技术将会是GPU性能维持指数级增长背后的关键。
第一个技术就是领域专用(domain-specific)芯片设计。
同样是芯片,GPU性能可以指数级增长而CPU却做不到,其中的一个重要因素就是GPU性能增长不仅仅来自于晶体管性能提升和电路设计改进,更来自于使用领域专用设计的思路。例如,在2016年之前,GPU支持的计算主要是32位浮点数(fp32),这也是在高性能计算领域的默认数制;但是在人工智能兴起之后,研究表明人工智能并不需要32位浮点数怎么高的精度,而事实上16位浮点数已经足够用于训练,而推理使用8位整数甚至4位整数都够了。而由于低精度计算的开销比较小,因此使用领域专用计算的设计思路,为这样的低精度计算做专用优化可以以较小的代价就实现人工智能领域较大的性能提升。从Nvidia GPU的设计我们可以看到这样的思路,我们看到了计算数制方面在过去的10年中从fp32到fp16到int8和int4的高效支持,可以说是一种低成本快速提高性能的思路。除此之外,还有对于神经网络的支持(TensorCore),稀疏计算的支持,以及Transformer的硬件支持等等,这些都是领域专用设计在GPU上的很好体现。在未来,GPU性能的提升中,可能是有很大一部分来自于这样的领域专用设计,往往一两个专用加速模块的引入就能打破最新人工智能模型的运行瓶颈来大大提升整体性能,从而实现四两拨千斤的效果。
第二个技术就是高级封装技术。
高级封装技术对于GPU的影响来自两部分:高速内存和更高的集成度。在大模型时代,随着模型参数量的进一步提升,内存访问性能对于GPU整体性能的影响越来越重要——即使GPU芯片本身性能极强,但是内存访问速度不跟上的话,整体性能还是会被内存访问带宽所限制,换句话说就是会遇到“内存墙”问题。为了避免内存访问限制整体性能,高级封装是必不可少的,目前的高带宽内存访问接口(例如已经在数据中心GPU上广泛使用的HBM内存接口)就是一种针对高级封装的标准,而在未来我们预期看到高级封装在内存接口方面起到越来越重要的作用,从而助推GPU性能的进一步提升。高级封装对于GPU性能提升的另一方面来自于更高的集成度。最尖端半导体工艺(例如3nm和以下)中,随着芯片规模变大,芯片良率会遇到挑战,而GPU可望是未来芯片规模提升最激进的芯片品类。在这种情况下,使用芯片粒将一块大芯片分割成多个小芯片粒,并且使用高级封装技术集成到一起,将会是GPU突破芯片规模限制的重要方式之一。目前,AMD的数据中心GPU已经使用上了芯片粒高级封装技术,而Nvidia预计在不久的未来也会引入这项技术来进一步继续提升GPU芯片集成度。
最后,高速数据互联技术将会进一步确保GPU分布式计算性能提升。如前所述,大模型的算力需求提升速度是每两年750倍,远超GPU摩尔定律提升性能的速度。这样,单一GPU性能赶不上模型算力需求,那么就必须用数量来凑,即把模型分到多块GPU上进行分布式计算。未来几年我们可望会看到大模型使用越来越激进的分布式计算策略,使用数百块,上千块甚至上万块GPU来完成训练。在这样的大规模分布式计算中,高速数据互联将会成为关键,否则不同计算单元之间的数据交换将会成为整体计算的瓶颈。这些数据互联包括近距离的基于电气互联的SerDes技术:例如在Nvidia的Grace Hopper Superchip中,使用NVLINK C2C做数据互联,该互联可以提供高达900GB/s的数据互联带宽(相当于x16 PCIe Gen5的7倍)。另一方面,基于光互联的长距离数据互联也会成为另一个核心技术,当分布式计算需要使用成千上万个计算节点的时候,这样的长距离数据交换也会变得很常见并且可能会成为系统性能的决定性因素之一。
我们认为,在人工智能火热的年代,GPU将会进一步延续摩尔定律的故事,让性能指数级发展继续下去。为了满足人工智能模型对于性能强烈的需求,GPU将会使用领域专用设计、高级封装和高速数据互联等核心技术来维持性能的快速提升,而GPU以及它所在的人工智能加速芯片也将会成为半导体领域技术和市场进步的主要推动力。
来源:
https://view.inews.qq.com/k/20230830A0843J00
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
post_newreply
回复
使用道具
举报
返回列表
发帖
回复
发表回复
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
点击附件文件名添加到帖子内容中
描述
本版积分规则
发表回复
回帖并转播
回帖后跳转到最后一页
精选推荐
@所有织里人,这份国庆假期安全
名单公布!
首个全国生态日主场活动在湖州举
2023绿色低碳创新大会在湖州举行
《焦点访谈》关注湖州!
市共同富裕领导小组召开第五次会
织里镇家园志愿广场本周活动预告
防诈骗小课堂,提高警惕!
7天1检!常态化核酸检测提醒!
友情链接
浙沪导航
网站目录
关闭
站长推荐
/1
关注织里资讯微信公众号
关注织里资讯微信公众号
查看 »
浙江网络警察报警平台
经营性网站备案信息
湖州市公安局网监备案
不良信息举报中心
联系客服
关注微信
下载APP
返回顶部
返回列表
点击联系客服
在线时间:8:30-17:00
客服电话
13362228119
电子邮件
511400718@qq.com
扫一扫,关注我们
下载APP客户端
 /1
/1