官方微信
手机客户端
设为首页
收藏本站
扫一扫,关注我们
QQ登录
微信登录
登录
注册
我的空间
我的消息
我的积分
我的收藏
我的好友
我的相册
我的道具
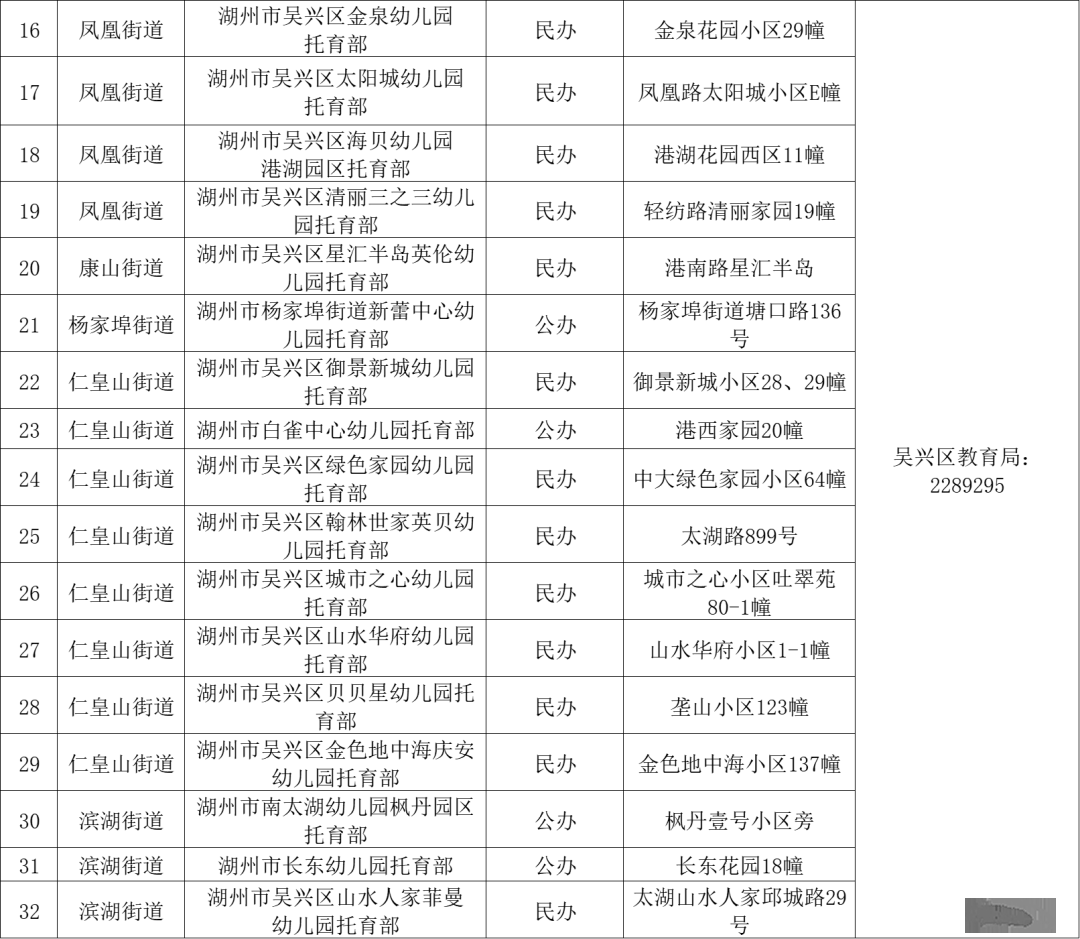
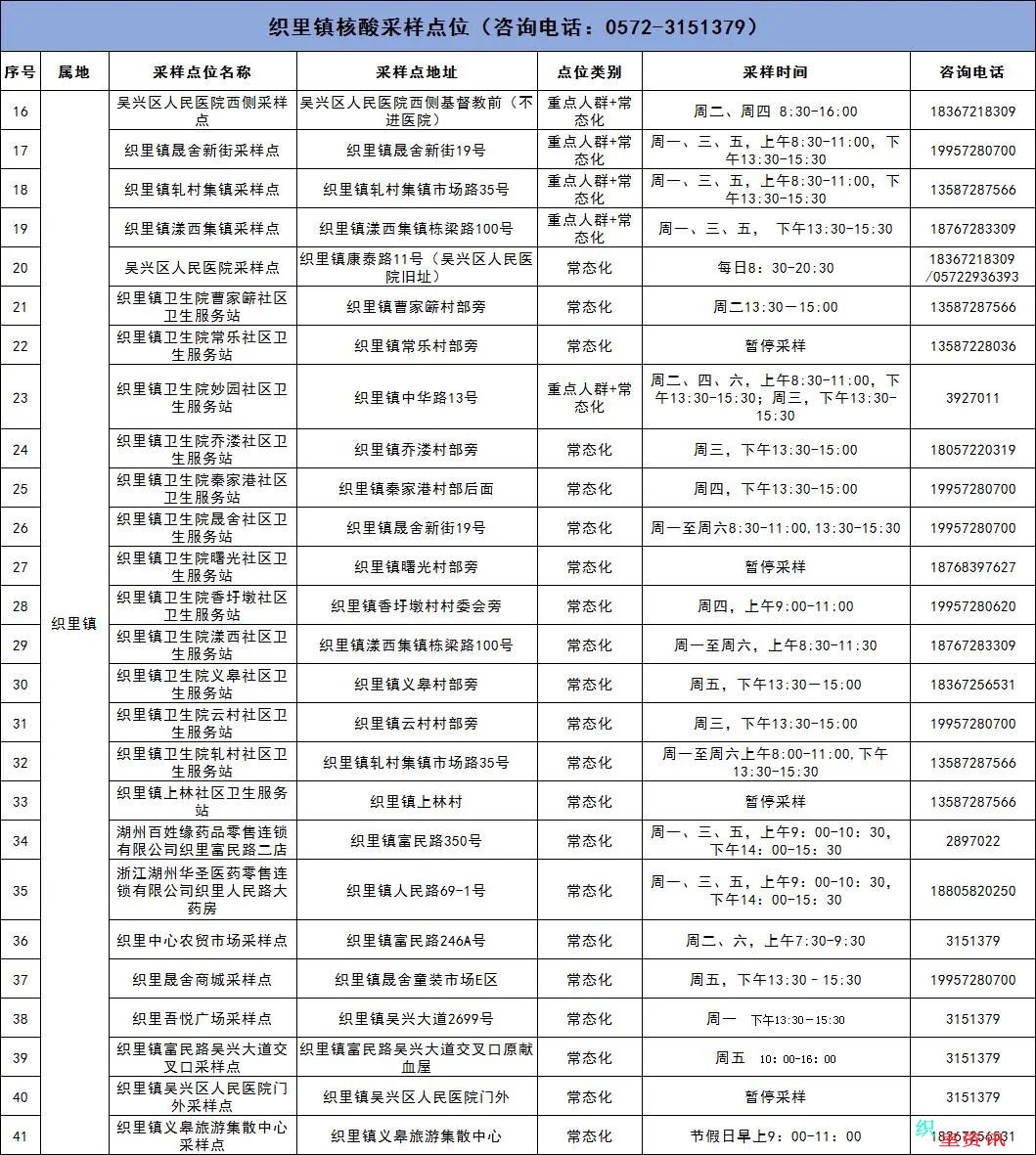
帐号设置
退出登录
免费发布信息
首页
Portal
新闻资讯
论坛
BBS
城事杂谈
求职招聘
房屋出租
织里跳蚤
房产资讯
关于我们
导读
首页
房产
装修
亲子
婚嫁
美食
汽车
旅游
娱乐
信息
求职
租房
二手房
招聘
拼车
二手车
服务
生活服务
城事杂谈
跳蚤市场
便民服务
社区
城事杂谈
情感天空
户外旅游
房产楼市
装修装饰
美食天地
当前位置:
»
论坛
›
城市服务
›
电脑维修
›
帖子
@所有织里人,这份国庆假期安全提
节前这场新闻发布会聚焦治安与共富
师傅,不好了!“二师兄”掉在高速
[ 理财 ]
12%是假酒,五粮液再“炮轰”电商平台
[ 电脑维修 ]
太阳可能存在旋转的极地涡旋 研究结果将
[ 学习教育 ]
教育孩子的“12法则”:永远让孩子看到希
[ 学习教育 ]
未成年人模式有新意,但效果要好还得靠家
[ 汽车天地 ]
不是本田奥德赛,别克GL8不够好,而是全
返回列表
发帖
回复
查看:
383
|
回复:
0
谁卡了英伟达的脖子?
[复制链接]
admin
admin
当前在线
积分
311244
关注TA
发消息
发表于 2023-11-20 19:23:35
|
来自:中国浙江湖州
|
显示全部楼层
|
阅读模式
英伟达最新季度财报公布后,不仅AMD沉默英特尔流泪,做过长时间心理建设的分析师也没想到真实情况如此超预期。
更可怕的是,英伟达同比暴涨854%的收入,很大程度上是因为“只能卖这么多”,而不是“卖出去了这么多”。一大堆“初创公司拿H100抵押贷款”的小作文背后,反应的是H100 GPU供应紧张的事实。
如果缺货继续延续到今年年底,英伟达的业绩恐怕会更加震撼。
H100的短缺不禁让人想起几年前,GPU因为加密货币暴涨导致缺货,英伟达被游戏玩家骂得狗血淋头。不过当年的显卡缺货很大程度上是因为不合理的溢价,H100的缺货却是产能实在有限,加价也买不到。
换句话说,英伟达还是赚少了。
在财报发布当天的电话会议上,“产能”理所当然地成为了最高频词汇。对此,英伟达措辞严谨,不该背的锅坚决不背:
“市场份额方面,不是仅靠我们就可以获得的,这需要跨越许多不同的供应商。”
实际上,英伟达所说的“许多不同的供应商”,算来算去也就两家:
SK海力士
和
台积电
。
HBM:韩国人的游戏
如果只看面积占比,一颗H100芯片,属于英伟达的部分只有50%左右。
在芯片剖面图中,H100裸片占据核心位置,两边各有三个HBM堆栈,加起面积与H100裸片相当。
这六颗平平无奇的内存芯片,就是H100供应短缺的罪魁祸首之一。
HBM(High Bandwidth Memory)
直译过来叫高宽带内存,在GPU中承担一部分存储器之职。
和传统的DDR内存不同,HBM本质上是将多个DRAM内存在垂直方向堆叠,这样既增加了内存容量,又能很好的控制内存的功耗和芯片面积,减少在封装内部占用的空间。
“堆叠式内存”原本瞄准的是对芯片面积和发热非常敏感的智能手机市场,但问题是,由于生产成本太高,智能手机最终选择了性价比更高的LPDDR路线,导致堆叠式内存空有技术储备,却找不到落地场景。
直到2015年,市场份额节节败退的AMD希望借助4K游戏的普及,抄一波英伟达的后路。
在当年发布的AMD Fiji系列GPU中,AMD采用了与SK海力士联合研发的堆叠式内存,并将其命名为HBM(High Bandwidth Memory)。
AMD的设想是,4K游戏需要更大的数据吞吐效率,HBM内存高带宽的优势就能体现出来。当时AMD的Radeon R9 Fury X显卡,也的确在纸面性能上压了英伟达Kepler架构新品一头。
但问题是,HBM带来的带宽提升,显然难以抵消其本身的高成本,因此也未得到普及。
直到2016年,AlphaGo横扫冠军棋手李世石,深度学习横空出世,让HBM内存一下有了用武之地。
深度学习的核心在于通过海量数据训练模型,确定函数中的参数,在决策中带入实际数据得到最终的解。
理论上来说,数据量越大得到的函数参数越可靠,这就让AI训练对数据吞吐量及数据传输的延迟性有了一种近乎病态的追求,而这恰恰是HBM内存解决的问题。
2017年,AlphaGo再战柯洁,芯片换成了Google自家研发的TPU。在芯片设计上,从第二代开始的每一代TPU,都采用了HBM的设计。英伟达针对数据中心和深度学习的新款GPU Tesla P100,搭载了第二代HBM内存(HBM2)。
随着高性能计算市场的GPU芯片几乎都配备了HBM内存,存储巨头们围绕HBM的竞争也迅速展开。
目前,全球能够量产HBM的仅有存储器三大巨头:
SK海力士、三星电子、美光。
SK海力士是HBM发明者之一,是目前唯一量产HBM3E(第三代HBM)的厂商;三星电子以HBM2(第二代HBM)入局,是英伟达首款采用HBM的GPU的供应商;美光最落后,2018年才从HMC转向HBM路线,2020年年中才开始量产HBM2。
其中
,
SK海力士独占HBM 50%市场份额,而其独家供应给英伟达的HBM3E,更是牢牢卡住了H100的出货量:
H100 PCIe和SXM版本均用了5个HBM堆栈,H100S SXM版本可达到6个,英伟达力推的H100 NVL版本更是达到了12个。按照研究机构的拆解,单颗16GB的HBM堆栈,成本就高达240美元。那么H100 NVL单单内存芯片的成本,就将近3000美元。
成本还是小问题,考虑到与H100直接竞争的谷歌TPU v5和AMD MI300即将量产,后两者同样将采用HBM3E,陈能更加捉襟见肘。
面对激增的需求,据说SK海力士已定下产能翻番的小目标,着手扩建产线,三星和美光也对HBM3E摩拳擦掌,但在半导体产业,扩建产线从来不是一蹴而就的。
按照9-12个月的周期乐观预计,HBM3E产能至少也得到明年第二季度才能得到补充。
另外,就算解决了HBM的产能,H100能供应多少,还得看台积电的脸色。
CoWoS:台积电的宝刀
分析师Robert Castellano不久前做了一个测算,H100采用了台积电4N工艺(5nm)生产,一片4N工艺的12寸晶圆价格为13400美元,理论上可以切割86颗H100芯片。
如果不考虑生产良率,那么每生产一颗H100,台积电就能获得155美元的收入[6]。
但实际上,每颗H100给台积电带来的收入很可能超过1000美元,原因就在于H100采用了台积电的CoWoS封装技术,通过封装带来的收入高达723美元[6]。
每一颗H100从台积电十八厂的N4/N5产线上下来,都会运往同在园区内的台积电先进封测二厂,完成H100制造中最为特别、也至关重要的一步——
CoWoS
。
要理解CoWoS封装的重要性,依然要从H100的芯片设计讲起。
在消费级GPU产品中,内存芯片一般都封装在GPU核心的外围,通过PCB板之间的电路传递信号。
比如下图中同属英伟达出品的RTX4090芯片,GPU核心和GDDR内存都是分开封装再拼到一块PCB板上,彼此独立。
GPU和CPU都遵循着冯·诺依曼架构,其核心在于“存算分离”——即芯片处理数据时,需要从外部的内存中调取数据,计算完成后再传输到内存中,一来一回,都会造成计算的延迟。同时,数据传输的“数量”也会因此受限制。
可以将GPU和内存的关系比作上海的浦东和浦西,两地间的物资(数据)运输需要依赖南浦大桥,南浦大桥的运载量决定了物资运输的效率,这个运载量就是内存带宽,它决定了数据传输的速度,也间接影响着GPU的计算速度。
1980年到2000年,GPU和内存的“速度失配”以每年50%的速率增加。也就是说,就算修了龙耀路隧道和上中路隧道,也无法满足浦东浦西两地物资运输的增长,这就导致高性能计算场景下,带宽成为了越来越明显的瓶颈。
2015年,AMD在应用HBM内存的同时,也针对数据传输采用了一种创新的解决方案:
把浦东和浦西拼起来。
简单来说,2015年的Fiji架构显卡,将HBM内存和GPU核心“缝合”在了一起,把几块小芯片变成了一整块大芯片。这样,数据吞吐效率就成倍提高。
不过如上文所述,由于成本和技术问题,AMD的Fiji架构并没有让市场买账。但深度学习的爆发以及AI训练对数据吞吐效率不计成本的追求,让“芯片缝合”有了用武之地。
另外,AMD的思路固然好,但也带来了一个新问题——无论HBM有多少优势,它都必须和“缝芯片”的先进封装技术配合,两者唇齿相依。
如果说HBM内存还能货比三家,那么“缝芯片”所用的先进封装,看来看去就只有台积电一家能做。
CoWoS是台积电先进封装事业的起点,英伟达则是第一个采用这一技术的芯片公司。
CoWoS由CoW和oS组合而来:
CoW表示Chip on Wafer,指裸片在晶圆上被拼装的过程,oS表示onSubstrate,指在基板上被封装的过程。
传统封装一般只有oS环节,一般在代工厂完成晶圆制造后,交给第三方封测厂解决,但先进封装增加的CoW环节,就不是封测厂能解决的了的。
以一颗完整的H100芯片为例,H100的裸片周围分布了多个HBM堆栈,通过CoW技术拼接在一起。但不只是拼接而已,还要同时实现裸片和堆栈间的通信。
台积电的CoW区别于其他先进封装的亮点在于,是将裸片和堆栈放在一个硅中介层(本质是一块晶圆)上,在中介层中做互联通道,实现裸片和堆栈的通信。
类似的还有英特尔的EMIB,区别在于通过硅桥实现互联。但带宽远不及硅中介层,考虑到带宽与数据传输速率息息相关,CoWoS便成了H100的唯一选择。
这便是卡住H100产能的另一只手。
虽然CoWoS效果逆天,但4000-6000美元/片的天价还是拦住了不少人,其中就包括富可敌国的苹果。因此,台积电预备的产能相当有限。
然而,AI浪潮突然爆发,供需平衡瞬间被打破。
早在6月就有传言称,今年英伟达对CoWoS的需求已经达到4.5万片晶圆,而台积电年初的预估是3万片,再加上其他客户的需求,产能缺口超过了20%。
为了弥补缺口,台积电的阵仗不可谓不大。
6月,台积电正式启用同在南科的先进封测六厂,光无尘室就比其余封测厂的加起来还大,并承诺逐季增加CoWoS产能,为此将部分oS外包给第三方封测厂。
但正如HBM扩产不易,台积电扩产也需要时间。
目前,部分封装设备、零组件交期在3-6个月不等,到年底前,新产能能开出多少仍是未知。
不存在的Plan B
面对H100的结构性紧缺,英伟达也不是完全没有Plan B。
在财报发布后的电话会议上,英伟达就透露,CoWoS产能已经有其他供应商参与认证。虽然没说具体是谁,但考虑到先进封装的技术门槛,除了台积电,也就只有英特尔先天不足的EMIB、三星开发了很久一直等不来客户的I-Cube能勉强救火。
但核心技术更换如同阵前换将,随着AMD MI300即将量产出货,AI芯片竞争白热化,是否能和英特尔和三星的技术磨合到位,恐怕黄仁勋自己心理也是惴惴。
比黄仁勋更着急的可能是买不到H100的云服务厂商与AI初创公司。毕竟游戏玩家抢不到显卡,也就是游戏帧数少了20帧;大公司抢不到H100,很可能就丢掉了几十亿的收入和上百亿的估值。
需要H100的公司主要有三类:微软、亚马逊这类云服务商;Anthropic、OpenAI这些初创公司;以及特斯拉这类大型科技公司,特斯拉的新版本FSD方案就用了10000块H100组成的GPU集群来训练。
这还没算上Citadel这类金融公司,以及买不到特供版H800的中国公司。
根据GPUUtils的测算[7],保守估计,目前H100的供给缺口达到43万张。
虽然H100存在理论上的替代方案,但在实际情况下都缺乏可行性。
比如H100的前代产品A100,价格只有H100的1/3左右。但问题是,H100的性能比A100强了太多,导致H100单位成本的算力比A100高。考虑到科技公司都是成百上千张起购,买A100反而更亏。
AMD是另一个替代方案,而且纸面性能和H100相差无几。但由于英伟达CUDA生态的壁垒,采用AMD的GPU很可能让开发周期变得更长,而采用H100的竞争对手很可能就因为这点时间差,和自己拉开了差距,甚至上亿美元的投资血本无归。
种种原因导致,一颗整体物料成本3000美元的芯片,英伟达直接加个零卖,大家居然都抢着买。这可能是黄仁勋自己也没想到的。
而在HBM与CoWoS产能改善之前,买到H100的方法可能就只剩下了一种:
等那些靠吹牛逼融到钱买了一堆H100的初创公司破产,然后接盘他们的二手GPU。
参考资料
[1]AI Capacity Constraints - CoWoS and HBM Supply Chain,SemiAnalysis
[2]原厂积极扩产,预估2024年HBM位元供给年成长率105%,TrendForce
[3]HBM技术会给数据中心带来怎样的变化?半导体产业纵横
[4]先进封装第二部分:英特尔、台积电、三星、AMD、日月光、索尼、美光、SKHynix、YMTC、特斯拉和英伟达的选项/使用回顾,Semianalysis
[5]OpenAI联合创始人兼职科学家Andrej Karpathy推文
[6]Taiwan Semiconductor: Significantly Undervalued As Chip And Package Supplier To Nvidia,SeekingAlpha
[7]Nvidia H100 GPUs: Supply and Demand,GPU Utils
编辑:李墨天
视觉设计:疏睿
责任编辑:李墨天
来源:
https://view.inews.qq.com/k/20230829A08WGQ00
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
post_newreply
回复
使用道具
举报
返回列表
发帖
回复
发表回复
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
点击附件文件名添加到帖子内容中
描述
本版积分规则
发表回复
回帖并转播
回帖后跳转到最后一页
精选推荐
@所有织里人,这份国庆假期安全
名单公布!
首个全国生态日主场活动在湖州举
2023绿色低碳创新大会在湖州举行
《焦点访谈》关注湖州!
市共同富裕领导小组召开第五次会
织里镇家园志愿广场本周活动预告
防诈骗小课堂,提高警惕!
7天1检!常态化核酸检测提醒!
友情链接
浙沪导航
网站目录
关闭
站长推荐
/1
关注织里资讯微信公众号
关注织里资讯微信公众号
查看 »
浙江网络警察报警平台
经营性网站备案信息
湖州市公安局网监备案
不良信息举报中心
联系客服
关注微信
下载APP
返回顶部
返回列表
点击联系客服
在线时间:8:30-17:00
客服电话
13362228119
电子邮件
511400718@qq.com
扫一扫,关注我们
下载APP客户端
 /1
/1